Эти и подобные им проблемы привлекают внимание исследователей в области искусственного интеллекта, которые стремятся улучшить наши представления о разуме человека. В частности, создаются интеллектуальные системы, которые подражают некоторым аспектам поведения человека. Ерман, Ларк и Хайес-Рот указывали, что "интеллектуальные системы отличаются от традиционных рядом признаков (не все из них обяэательны):
Успехи энтузиастов в этой области несколько преувеличены; но, тем не менее, искусственный интеллект дал немало хороших практических идей, в частности представление знаний, концепция информационной доски и экспертные системы [2]. В данной главе рассматриваются подходы к созданию интеллектуальной системы расшифровки криптограмм на основе метода информационной доски, в достаточной степени моделирующего человеческий способ решения задачи. Как мы увидим, методы объектно-ориентированного проектирования очень хорошо работают в этой области.
11.1. Анализ
Определение границ предметной области
Как сказано во врезке, мы намерены заняться криптоанализом - процессом преобразования зашифрованного текста в обычный. В общем случае процесс дешифровки является чрезвычайно сложным и не поддается даже самым мощным научным методам. Существует, например, стандарт шифрования DES (Data Encryption Standard, алгоритм шифрования с закрытым ключом, в котором используются многочисленные подстановки и перестановки), который, по-видимому, свободен от слабых мест и устойчив ко всем известным методам взлома. Но наша задача значительно проще, поскольку мы ограничимся шифрами с одной подстановкой.
В качестве первого шага анализа попробуйте решить (только честно, не заглядывая вперед!) следующую криптограмму записывая, каждый ваш шаг:
Q AZWS DSSC KAS DXZNN DASNN
Подсказка: буква w соответствует букве v исходного текста. Перебор всех возможных вариантов совершенно лишен смысла. Предполагая, что алфавит содержит 26 прописных английских букв, получим 26! (около 4.03х1026) возможных комбинаций. Следовательно, нужно искать другой метод решения, например, использовать знания о структуре слов и предложений и делать правдоподобные допущения. Как только мы исчерпаем явные решения, мы сделаем наиболее вероятное предположение и будем продвигаться дальше. Если обнаружится, что предположение приводит к противоречию или заводит в тупик, мы вернемся назад и сделаем другую попытку.
| Требования к системе криптоанализа
Криптография "изучает методы сокрытия данных от посторонних" [3]. Криптографические алгоритмы преобразовывают сообщения (исходный текст) в зашифрованный текст (криптограмму) и наоборот. Одним из наиболее общеупотребительных (еще со времен Древнего Рима) криптографических алгоритмов является подстановка. Каждая буква в алфавите исходного текста заменяется другой буквой. Например, можно циклически сдвинуть все буквы алфавита: буква A заменяется на B, B на C, a Z на A. Тогда следующий исходный текст: CLOS is an object-oriented programming language превращается в криптограмму: DMPT jt bo pckfdu-psjfoufe qsphsbnnjoh mbohvbhf Чаще всего замена делается менее тривиальным образом. Например, A заменяется на G, B на J и т.д. Рассмотрим следующую криптограмму: PDG TBCER CQ TCK AL S NGELCH QZBBR SBAJG Подсказка: буква C в этой криптограмме соответствует букве O исходного текста. Существенно упрощает задачу предположение о том, что для шифрования текста использован алгоритм подстановки, поскольку в общем случае процесс дешифровки не будет столь тривиальным. В процессе расшифровки приходится использовать метод проб и ошибок, когда мы делаем предположение о замене и рассматриваем его следствия. Удобно, например, начать расшифровку с предположения о том, что одно- и двухбуквенные слова в криптограмме соответствуют наиболее употребительным словам английского языка (I, a, or, it, in, of, on). Подставляя эти предполагаемые буквы в другие слова, мы можем догадаться о вероятном значении других букв. Например, если трехбуквенное слово начинается с литеры O, то это могут быть слова one, our, off. Знание фонетики и грамматики также может способствовать дешифровке. Например, следование подряд двух одинаковых литер с очень малой вероятностью может означать qq. Наличие в окончании слова буквы g позволяет сделать предположение о наличии суффикса ing. На еще более высоком уровне абстракции логично предположить, что словосочетание it is более вероятно, чем if is. Необходимо учитывать и структуру предложения: существительные и глаголы. Если выясняется, что в предложении есть глагол, но нет существительного, которое с ним связано, то нужно отвергнуть сделанные ранее предположения н начать поиск заново. Иногда приходится возвращаться назад, если сделанное предположение вступает в противоречие с другими предположениями. Например, мы допустили, что некоторое двухбуквенное слово соответствует сочетанию or, что в дальнейшем привело к противоречию. В этом случае мы должны вернуться назад и попытаться использовать другой вариант расшифровки этого слова, например, on. Требования к нашей системе: по данной криптограмме, в предположении, что использована простая подстановка, найти эту подстановку и (главное) восстановить исходный текст. |
1. Используя подсказку, заменим w на v.
Q AZVS DSSC KAS DXZNN DASNN
2. Первое слово из одной буквы, вероятна, A или I; предположим, что это A:
A AZVS DSEC KAS DXZNN DASNN
3. В третьем слове должны быть гласные звуки и вероятно, что это двойные буквы. Это не могут быть UU или II, а также AA (буква A уже использована). Попробуем вариант EE.
A AZVE DEEC KAE DXZNN DAENN
4. Четвертое слово состоит из трех букв и оканчивается на E, это очень похоже на слово THE.
A HZVE DEEC THE DXZNN DHENN
5. Во втором слове нужна гласная, и здесь подходят только I, O, U (буква A уже использована). Только вариант с буквой I дает осмысленное слово.
A HIVE DEEC THE DXINN DHENN
6. Можно найти несколько слов с двойной буквой E из четырех букв (DEER, BEER, SEEN). Грамматика требует, чтобы третье слово было глаголом, поэтому остановимся на SEEN.
A HIVE SEEN THE SXINN SHENN
7. Смысл в полученном предложении отсутствует, поскольку улей (HIVE) не может видеть (SEEN), значит, где-то по дороге мы сделали ошибку. Похоже, что выбор гласной буквы во втором слове был неверен, и приходится вернуться назад, отменив самое первое предположение - первым словом должно быть I. Повторяя все остальные наши рассуждения практически без изменений мы получаем:
I HAVE SEEN THE SXANN SHENN
8. Посмотрим на два последних слова. Двойная буква S в конце не дает осмысленного значения и к тому же уже использована ранее, а вот LL дает осмысленное слово.
I HAVE SEEN THE SXALL SHELL
9. Из грамматических соображений очевидно, что оставшееся слово - прилагательное. Анализируя шаблон S?ALL, находим SMALL.
I HAVE SEEN THE SMALL SHELL
Таким образом, решение найдено. Анализируя процесс решения, мы можем сделать три наблюдения:
Информационная доска вполне подходит на роль среды разработки (см. главу 9). Попробуем теперь зафиксировать архитектуру этого метода в виде системы классов и механизмов их взаимодействия.
Архитектура метафоры информационной доски
Энглемор и Морган для пояснения модели информационной доски использовали следующую аналогию с группой людей, собирающей фрагменты головоломки в нужную фигуру:
Вообразим себе комнату с большой доской, рядом с которой находится группа людей, держащих в руках фрагменты изображения. Процесс начинают добровольцы, которые размещают на доске наиболее "вероятные" фрагменты изображения (предположим, что они прилепляются к доске). Далее каждый участник группы смотрит на оставшиеся у него фрагменты и решает, есть ли такие, которые подходят к уже находящимся на доске. Участник, нашедший соответствие, подходит к доске и прилепляет свой кусок. В результате фрагмент за фрагментом занимают нужное место. При этом не существенно, что один из участников может иметь больше фрагментов, чем другой. Все изображение будет полностью собрано без всякого обмена информацией между членами группы. Каждый участник активизируется самостоятельно и знает, когда ему нужно включиться в процесс. Никакого порядка подхода к доске заранее не устанавливается. Совместное поведение регулируется только информацией на доске. Наблюдение за процессом демонстрирует его последовательность (по одному фрагменту за подход) и произвольность (когда возникает возможность, фрагмент устанавливается). Это существенно отличается от строгой систематичности, например, от прохождения с левого верхнего угла и перебора каждого фрагмента [7].
Из рис. 11-1 видно, что основу метода составляют три элемента: информационная доска, совокупность источников знаний и управляющий этими источниками контроллер [8]. Отметим, что следующее определение прямо соответствует принципам объектного подхода. Согласно Ни: "Информационная доска нужна для того чтобы хранить данные о ходе и состоянии решаемой задачи, используемые и формируемые источниками знаний. Доска содержит объекты из пространства решений. Эти объекты иерархически группируются по уровням анализа и вместе со своими атрибутами образуют словарь пространства решений" [9].
Энглемор и Морган уточняют: "необходимые для решения задачи знания о предметной области разделены на несколько независимых источников. Каждый источник знаний старается предложить информацию, полезную для решения за дачи. Текущая информация из каждого источника помещается на доске и модифицируется в соответствии с содержанием знаний. Формой представления источников знаний являются процедуры, наборы правил или логические заключения" [10].

Источники знаний зависят от предметной области. В системах распознавания речи нас могут интересовать агенты, поставляющие знания о фонемах, словах и предложениях. В системах распознавания образов ими могут быть сведения об элементарных структурах изображения, таких, как стыки линий, участки одинаковой плотности, и, на более высоком уровне абстракции, объекты, относящиеся к конкретной сцене (дома, дороги, поля, автомобили и люди).
В общем случае источники знаний соответствуют иерархической структуре объектов, размещаемых на информационной доске. Более того, каждый источник использует объекты одного уровня иерархии в качестве входных данных, а в качестве выхода генерирует или изменяет объекты на другом уровне. Например, в системе распознавания речи источник знаний о словах наблюдает за потоком фонем (низкий уровень абстракции), чтобы обнаружить слово (более высокий уровень абстракции). Источник знаний о предложениях может предположить, что здесь нужен глагол (высокий уровень абстракции) и проверить это предположение, перебрав список возможных слов (низкий уровень абстракции).
Эти два подхода к поиску решения называются соответственно прямой и обратной последовательностью рассуждений. Прямая последовательность рассуждений позволяет перейти от более частных предположений к более общим, а обратная последовательность, отталкиваясь от некоторой гипотезы, позволяет проверить ее, сравнив с известными предпосылками. Вот почему управление информационной доской мы охарактеризовали как произвольное: в зависимости от обстоятельств, источники знаний могут активизировать либо прямые, либо обратные последовательности рассуждений.
Источники знаний, как правило, состоят из двух компонент: предусловия и действия. Предусловием называется такое состояние информационной доски, которое представляет "интерес" для конкретного источника знаний (потенциально способно его активизировать). Например, в распознавании образов предусловием может быть наличие прямой линии (которая может означать дорогу). Выполнение предусловий заставляет источник знаний сфокусировать внимание на конкретном участке информационной доски, а затем привести в действие соответствующие правила или процедурные знания.
В этих условиях очередность активизации не имеет значения: если источник знаний обнаруживает данные, полезные для решения задачи, он сигнализирует об этом контроллеру доски, фигурально выражаясь, он как бы поднимает руку, показывая, что желает сделать что-то полезное. Из нескольких источников, делающих такой жест, контроллер вызывает того, кто ему представляется наиболее перспективным.
Анализ источников знаний
Вернемся теперь к поставленной задаче и рассмотрим источники знаний, полезные для ее решения. При построении большинства приложений, основанных на знаниях, лучше всего сесть рядом с экспертом в предметной области и фиксировать те эвристики, которые он использует. В нашем случае придется попытаться расшифровать некоторое количество криптограмм и отметить особенности процесса поиска решений.
Действуя таким образом мы выявили тринадцать источников знаний, относящихся
к нашей проблеме:
| • Префиксы | Наиболее часто используемые начала слов (например, re, anti, un). |
| • Суффиксы | Наиболее часто используемые окончания слов (ly, ing, es, ed). |
| • Согласные | Буквы, не являющиеся гласными. |
| • Непосредственно известные подстановки | Подстановки, известные нам априори, до решения задачи. |
| • Двойные буквы | Наиболее часто сдваиваемые буквы (tt, ll, ss). |
| • Частота букв | Вероятность появления букв в тексте. |
| • Правильные строки | Допустимые и недопустимые сочетания букв (например, qu и zg). |
| • Сравнение с шаблоном | Слова, соответствующие шаблону. |
| • Структура фраз | Грамматика, включая знания об именных и глагольных оборотах. |
| • Короткие слова | Одно-, двух-, трех- и четырехбуквенные слова. |
| • Решение | Найдено ли решение или мы зашли в тупик. |
| • Гласные | Буквы, не являющиеся согласными. |
| • Структура слова | Расположение гласных и типичная структура существительных, глаголов, прилагательных, наречий, предлогов, союзов и т.д. |
Перечисленные источники знаний можно организовать в иерархию. В частности, существуют группы источников знаний о предложениях, о словах, о группах букв и об отдельных буквах. Такая иерархия соответствует объектам на информационной доске: предложениям, словам, частям слов и буквам.
11.2. Проектирование
Архитектура информационной доски
Теперь у нас есть все, чтобы приступить к решению поставленной задачи с использованием метафоры информационной доски. Это классический пример повторного использования "в большом": мы повторно применяем испытанный архитектурный шаблон как основу проекта. Метод информационной доски предполагает следующие объекты верхнего уровня: информационная доска, несколько источников знаний и контроллер. Остается только определить классы и объекты предметной области, которые специализируют эти общие абстракции.
Объекты информационной доски. Объекты на доске образуют иерархию, отражающую иерархичность различных уровней абстракции источников знаний. Таким образом, у нас есть три следующих класса:
class BlackboardObject ...
С точки зрения внешнего поведения определим для этого класса две операции:
Зависимости и подтверждения. Предложения, слова и буквы также связаны определенной общностью: для всех них есть соответствующие источники знаний. Конкретный источник знаний, со своей стороны, может проявлять интерес к одному или нескольким таким объектам (зависеть от них) и поэтому фраза, слово и символ шифра должны поддерживать связь с источником знаний, чтобы при появлении предположения относительно объекта уведомлялись соответствующие источники знаний. Это напоминает механизм зависимостей языка Smalltalk, упомянутый в главе 4. Для реализации этого механизма введем следующий класс-примесь:
class Dependent {
public:
Dependent();...
Dependent(const Dependent&);
virtual ~Dependent();
UnboundedCollection<KnowledgeSource*> references;};
Мы забежали несколько вперед и намекнули на возможную реализацию класса, чтобы показать связь с библиотекой фундаментальных классов, описанной в главе 9. В классе определен один внутренний элемент - коллекция указателей на источники знаний [В главе 9 мы отмечали, что неограниченные структуры требуют менеджера памяти. Для простоты мы опускаем этот аргумент шаблона всюду в данной главе. Конечно, полная реализация должна быть согласована с механизмами среды разработки].
Определим для этого класса следующие операции:
Зависимость может примешиваться к другим классам. Например, буква шифра - это объект информационной доски, от которого зависят другие, так что мы можем скомбинировать две этих абстракции для получения нужного поведения. Такое применение примесей поощряет повторное использование и разделение понятий в нашей архитектуре.
Символы шифра и алфавиты имеют еще одно общее свойство: относительно объектов этих классов могут делаться предположения. Вспомните, что предположение (Assumption) является одним из объектов на доске (BlackboardObject). Так, некоторый источник знаний может допустить, что буква K в шифре соответствует букве P исходного текста. По мере решения задачи может абсолютно точно выясниться, что G означает J. Поэтому введен еще один класс:
class Affirmation ...
Этот класс отвечает за высказывания (предположения или утверждения) относительно связанного с ним объекта. Мы используем этот класс не как примесь, а для агрегации. Буква, например, не является предположением, но может иметь предположение о себе.
В нашей системе предположения допускаются только в отношении отдельных букв и алфавитов. Можно, например, предположить, что какая-либо буква шифра соответствует некоторой букве алфавита. Алфавит состоит из набора букв, относительно которых делаются предположения. Определяя Affirmation как независимый класс, мы выражаем в нем сходное поведение этих двух классов, несвязанных наследованием.
Определим следующий набор операций для экземпляров этого класса:
class Assumption : public BlackboardObject
{
public:
...
BlackboardObject* target;};
KnowledgeSource* creator;
String<char> reason;
char plainLetter;
char cipherLetter;
Отметим, что мы повторно использовали еще один класс среды, описанной в главе 9, а именно, параметризуемый класс String.
Класс Assumption является объектом информационной доски, поскольку информация о сделанных предположениях используется всеми источниками знаний. Отдельные члены класса выражают следующие его свойства:
Далее определим подкласс Assertion:
class Assertion : public Assumption ...
Общим для классов Assumption и Assertion является следующий селектор:
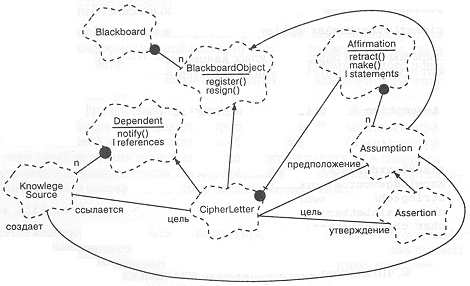
На рис. 11-2 приведена диаграмма, поясняющая связь классов зависимостей и высказываний. Обратите особое внимание на роли, которые играют упомянутые абстракции в различных ассоциациях. Например, класс KnowledgeSource в одном аспекте является создателем (creator) предположения, а в другом - ссылается (referencer) на букву шифра. Из различия ролей естественным образом вытекают различия протоколов взаимодействия.
Проектирование объектов информационной доски. Завершим проектирование, добавив кроме класса алфавита классы для предложения (Sentence), слова (Word) и буквы шифра (cipherLetter). Предложение представляет собой просто объект доски (от которого зависят другие объекты), содержащий список слов, Исходя из этого, запишем:
class Sentence : public BlackboardObject, virtual public
Dependent {
public:
...
protected:
List<Word*> words;};
Суперкласс Dependent определен виртуальным, поскольку мы ожидаем, что будут подклассы от sentence, которые захотят наследовать также и от Dependent. При этом для всех таких подклассов члены класса Dependent будут общими.
В дополнение к операциям register и resign (определенным в суперклассе BlackboardObject) и четырем операциям, унаследованным от класса Dependent, мы добавляем еще две специфические операции для предложения:
Слово является объектом доски и источником зависимости. Оно состоит из букв. Для удобства источников знаний в класс слова введены указатели на все предложение, а также на предыдущее и следующее слова в предложении. Описание класса Word выглядит так:
class Word : public BlackboardObject, virtual public Dependent
{
public:
...
Sentence& sentence() const;protected:
Word* previous() const;
Word* next() const;
List<CipherLetter*> letters;};
Так же как для предложения, в класс слова введены две дополнительные операции:
class CipherLetter : public BlackboardObject, virtual
public Dependent {
public:
...
char value() const;...
int isSolved() const;
char letter;};
Affirmation affirmations;
Отметим, что и в этот класс добавлена та же пара селекторов по аналогии с классами слова и предложения. Для клиентов этого объекта нужно предусмотреть защищенные операции доступа к предположениям и утверждениям.
Объект affirmations, включенный в этот класс, содержит коллекцию предположений и утверждений в порядке их выдвижения. Последний элемент коллекции содержит текущее предположение или утверждение. Смысл хранения последовательности решения задачи состоит в возможности обучения источников знании на собственных ошибках. Поэтому в класс Affirmation введены два дополнительных селектора:
UnboundedOrderedCollection<Assumption*> statements;
Этот объект также позаимствован нами из библиотеки фундаментальных классов главы 9.
Теперь обратимся к классу Alphabet (алфавит). Он содержит данные об алфавитах исходного текста и шифра, а также о соответствии между ними. Эта информация необходима для того, чтобы источники знаний могли узнать о выявленных соответствиях между буквами шифра и текста и тех, которые еще предстоит найти. Например, если уже доказано, что буква с а шифре соответствует букве и исходного текста, то это соответствие фиксируется в алфавите и источники знаний уже не будут делать других предположений в отношении буквы м исходного текста. Для эффективности обработки полезно получать данные о соответствии букв шифра и текста двумя способами: по букве шифра и по букве исходного текста. Определим класс Alphabet следующим образом:
class Alphabet : public BlackboardObject {
public:
char plaintext(char) const;};
char ciphertext(char) const;
int isBound(char) const;
Так же, как и в класс CipherLetter, в класс Alphabet необходимо включить защищенный объект affirmations и определить операции доступа к его состоянию.
Наконец, определим класс Blackboard, который является коллекцией экземпляров класса Blackboardobject и его подклассов:
class Blackboard : public DynamicCollection<BlackboardObject*> ...
Поскольку доска есть разновидность коллекции (тест на наследование), мы предпочитаем образовать этот класс методом наследования, а не с помощью включения экземпляра класса DynamicCollectlon. Операции включения в коллекцию и исключения из нее наследуются от класса Collection, а следующие пять операций, специфичных для информационной доски, вводятся нами:

Обратите внимание на то, что класс Blackboard одновременно и инстанцирует от шаблона DynamicCollection, и наследует от него. Кроме того, становится понятным использование класса Dependent в качестве примеси. Не привязывая этот класс жестко к иерархии Blackboard, мы повышаем шансы на его последующее повторное использование.
Проектирование источников знаний
В предыдущем разделе мы выделили тринадцать источников знаний, относящихся к решаемой задаче. Теперь можно приступить к проектированию структур классов для них (как это было сделано для информационной доски) и обобщению их в более абстрактные классы.
Проектирование специализированных источников знаний. Предположим, что существует абстрактный класс KnowledgeSource (по аналогии с классом BlackboardObject). Прежде чем определять все тринадцать источников в качестве подклассов одного общего суперкласса, нужно посмотреть, не группируются ли они каким-нибудь образом. Действительно, такие группы находятся: некоторые источники знаний оперируют целым предложением, другие - словами, фрагментами слов или отдельными буквами. Отразим этот факт в следующих определениях:
class SentenceKnowledgeSource : public KnowledgeSource ...
class WordKnowledgeSource : public KnowledgeSource ...
class LetterKnowledgeSource : public KnowledgeSource ...
Для каждого из этих абстрактных классов в дальнейшем мы определим специализированные подклассы. Для класса SentenceKnowledgeSource они будут выглядеть следующим образом:
class SentenceStructureKnowledgeSource : public SentenceKnowledgeSource
...
class SolvedKnowledgeSource : public SentenceKnowledgeSource
...
Аналогично, подклассы класса WordKnowledgeSource определяются так:
class WordStructureKnowledgeSource : public WordKnowledgeSource
...
class SmallWordKnowledgeSource : public WordKnowledgeSource
...
class PatternMatchingKnowledgeSource : public WordKnowledgeSource
...
Последний класс требует некоторых пояснений. Ранее упоминалось, что его цель состоит в нахождении слов по шаблону. Для описания шаблона можно воспользоваться системой записи регулярных выражении, принятой, в частности, в утилите grep системы UNIX:
Поскольку проверка по шаблону является методом, полезным как для данной системы в целом, так и в других областях, соответствующий класс целесообразно выделить в качестве самостоятельной абстракции. Поэтому неудивительно, что мы воспользуемся классом из нашей библиотеки (см. главу 9). В результате наш класс для проверки по шаблону будет выглядеть следующим образом:
class PatternMatchingKnowledgeSource : public WordKnowledgeSource
{
public:
...
protected:
static BoundedCollection<Word*> words;};
REPatternMatching patternMatcher;
Все экземпляры этого класса разделяют общий словарь, но каждый из них может иметь собственного агента для сравнения с шаблонами.
На данном этапе проектирования подробности реализации этого класса для нас не существенны, поэтому мы не будем на них подробно останавливаться.
Определим теперь подклассы класса StringKnowledgeSource следующим образом:
class CommonPrefixKnowledgeSource : public StringKnowledgeSource
...
class CommonSuffixKnowledgeSource : public StringKnowledgeSource
...
class DoubleLetterKnowledgeSource : public StringKnowledgeSource
...
class LegalStringKnowledgeSource : public StringKnowledgeSource
...
Наконец, определим подклассы класса LetterKnowledgeSource:
class DirectSubstitutionKnowledgeSource : public LetterKnowledgeSource
...
class VowelKnowledgeSource : public LetterKnowledgeSource
...
class ConsonantKnowledgeSource : public LetterKnowledgeSource
...
class LetterFrequencyKnowledgeSource : public LetterKnowledgeSource
...
Общее в источниках знаний. Анализ показал, что только две операции определены для всех упомянутых специализированных классов:
class InferenceEngine {
public:
InferenceEngine(<DynamicSet<Rules*>);...
Конструктор класса создает экземпляр объекта и населяет его правилами. Лишь одна операция сделана в этом классе видимой для источников знании:

Что такое правило? Для иллюстрации приведем (в формате Lisp) правило, касающееся знаний об общеупотребительных суффиксах:
((* I ? ?)
(* I N G)
(* I E S)
(* I E D))
Это правило означает, что заданному шаблону *I?? (условие - antecedent) могут соответствовать суффиксы ING, IES и IED (заключение - consequent). В C++ можно определить следующий класс для представления правил:
class Rule {
public:
...
int bind(String<char>& antecedent, String<char>& consequent);protected:
int remove(Strlng<char>& antecedent);
int remove(String<char>t antecedent, String<char>& conseiruent);
int hasConflict(const String<char>& antecedent) const;
String<char> antecedent;};
List<String<char>> consequents;
Смысл приведенных операций полностью понятен из их наименований. Мы здесь повторно использовали некоторые классы из главы 9.
С точки зрения строения данного класса можно утверждать, что источники знаний являются разновидностью механизма вывода. Кроме того, они ассоциированы с объектами доски, поскольку находят там приложение своим усилиям. Наконец, каждый источник знаний связан с контроллером и посылает ему свои соображения. Контроллер, в свою очередь, может активизировать источники знаний.
Выразим все сказанное следующим образом:
class KnowledgeSource : public InferenceEngine, public
Dependent {
public:
KnowledgeSource(Blackboard*, Controller*);protected:
void reset();
void evaluate();
Blackboard* blackboard;};
Controller* controller;
UnboundedOrderedCollection<Assumption*> pastAssumptions;
В этот класс введен защищенный элемент данных pastAssumptions, позволяющий сохранять всю историю предположений в целях самообучения.
Экземпляры класса Blackboard служат для хранения объектов информационной доски. По схожим соображениям, необходим также класс KnowledgeSources, охватывающий все источники знаний, относящиеся к решаемой задаче:
class KnowledgeSources : public DynamicCollection<KnowledgeSource*> ...
Одно из свойств этого класса состоит в том, что при создании его экземпляра создаются также 13 специализированных источников знаний. Для объектов этого класса определяются три операции:

На рис. 11-5 показана структура созданных в процессе проектирования классов источников знаний.
Проектирование контроллера
Рассмотрим более подробно взаимодействие контроллера с отдельными источниками знаний. В процессе поэтапной расшифровки криптограммы отдельные источники знаний выявляют полезную информацию и сообщают ее контроллеру. С другой стороны, может быть обнаружено, что ранее переданная информация оказалась ложной и ее надо устранить. Поскольку все источники знаний имеют равные права, контроллер должен опросить их все, выбрать тот, информация которого кажется наиболее полезной, и разрешить ему внести изменения вызовом его операции evaluate.
Каким образом контроллер определяет, какой из источников знаний следует активизировать? Можно предложить несколько разумных правил:
Контроллер должен быть в ассоциативной связи с источниками знаний через класс KnowledgeSources. Кроме того, он должен иметь в качестве одного из своих свойств коллекцию высказываний, упорядоченных по приоритету. Тем самым контроллер легко может выбрать для активизации источник знаний с наиболее интересным высказыванием.
После изолированного анализа класса мы предлагаем ввести для класса controller следующие операции:
class Controller {
public:
...
void reset();};
void connect(Knowledgesource&);
void addHint(KnowledgeSource&);
void removeHint(KnowledgeSource&);
void processNextHint();
int isSolved() const;
int unableToProceed() const;
Контроллер в некотором смысле управляется источниками знаний, поэтому для описания его поведения наилучшим образом подходит схема конечного автомата.
Рассмотрим диаграмму состояний и переходов на рис. 11-6. Из нее видно, что контроллер может находиться в одном из пяти основных состояний: инициализация (Initializing), выбор (Selecting), вычисление (Evaluating), тупик (Stuck) и решение (Solved). Наибольший интерес для нас представляет поведение контроллера при переходе от выбора к вычислению. В состоянии selecting контроллер переходит от создания стратегии (CreatingStrategy) к вычислению высказывания (ProcessingHint) и, в конце концов, выбирает источник знаний (SelectingKS).
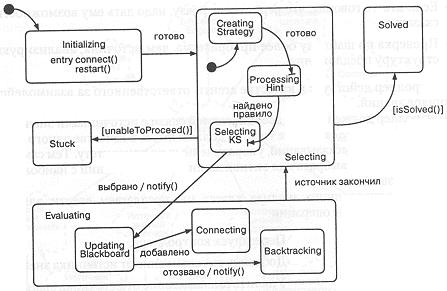
Дав одному из источников возможность высказаться, контроллер переходит в состояние Evaluating, где прежде всего изменяет состояние информационной доски. Это вызывает переход в состояние Connecting при добавлении источника знании или к Backtracking, если предположение не оправдалось и надо откатить его, оповестив при этом все зависимые источники знаний.
Конечной точкой работы нашего механизма является solved (задача решена) или stuck (тупиковая ситуация).
11.3. Эволюция
Интеграция
Теперь, когда ключевые абстракции предметной области выявлены, можно приступить к их соединению в действующее приложение. Мы будем реализовывать и проверять вертикальные срезы системы, а затем последовательно отрабатывать механизмы.
Интеграция объектов верхнего уровня. На рис. 11-7 показана диаграмма объектов нашей системы на самом верхнем уровне, которая полностью соответствует структуре информационной доски, приведенной на рис. 11-1. Физическое содержание объектов доски в коллекции theBlackboard и источников знаний в коллекции theKnowledgeSources показано в соответствии с описанием вложенности классов.
На диаграмме появился экземпляр класса Cryptographer. Он агрегирует объекты доски, источники знаний и контроллер. В результате наша программа может иметь несколько экземпляров этого класса, а следовательно и несколько досок, функционирующих параллельно.

Для этого класса следует определить две основные операции:
Метод decipher принимает строку - криптограмму. Теперь функции высокого уровня нашего приложения становятся предельно простыми, как это обычно и происходит в объектно-ориентированных системах:
char* solveProblem(char* ciphertext)
{
Cryptographer theCryptographer;}
return theCryptographer.decipher(ciphertext);
Метод decipher оказывается несколько сложнее. В первую очередь с помощью операции assertProblem задание помещается на доску. После этого активизируются источники знаний. И, наконец, начинается циклический процесс обращения источников знаний к контроллеру с новыми и новыми предположениями и утверждениями до тех пор, пока не будет найдено решение задачи либо процесс не зайдет в тупик. Для иллюстрации можно воспользоваться диаграммами взаимодействия или диаграммами объектов, но код на C++ выглядит тоже не слишком сложно:
theBlackboard.assertProblem();
theKnowledgeSources.reset();
while (!theController.isSolved || !theController.unableToProceed())
theController.processNextHint();if (theBlackboard.isSolved())
return theBlackboard.retrieveSolution();Теперь нам лучше всего дополнить алгоритм соответствующими архитектурными интерфейсами. Хотя в данный момент его дееспособность минимальна, но реализация в виде вертикального среза системной архитектуры позволяет проверить ключевые системные решения.
Посмотрим на две операции, определенные в классе decipher, а именно assertProblem и retrieveSolution. Первая из них интересна тем, что создает структуру доски. Опишем наш алгоритм следующим образом:
убрать из строки все начальные и концевые пробелы
if получилась пустая строка return
создать объект-предложение
занести предложение на доску
создать объект-слово (самое крайнее слева)
занести слово на доску
добавить слово к предложению
for каждый символ строки слева направо
if символ есть пробел
В главе 6 уже упоминалось, что целью проектирования является создание наброска реализации. Эта запись представляет достаточно детализированный алгоритм, так что показывать его полную реализацию на C++ нет необходимости.сделать текущее слово предыдущимelse
создать объект-слово
занести слово на доску
добавить слово к предложениюсоздать объект "буква шифра"
занести букву на доску
добавить букву к слову
Операция retrieveSolution очень проста: она возвращает строку, записанную в данный момент на доске. Вызывая эту операцию до того как функция isSolved вернула значение True, можно получать частичные решения.
Реализация механизма предположений. Итак, мы умеем устанавливать и извлекать значения объектов доски. Теперь нам нужен механизм выдвижения высказывании об этих объектах. Этот механизм интересен ввиду его динамичности. При поиске решения предположения непрерывно создаются и отзываются, чем как раз и приводится в действие весь процесс.
На рис. 11-8 показан сценарий выдвижения предположений. Источник знаний сообщает об имеющихся предположениях информационной доске, которая применяет их к алфавиту и оповещает остальные источники.
В простейшем случае, чтобы отменить предположение, мы просто прокручиваем этот механизм в другую сторону. Например, чтобы отменить предположение о букве, мы убираем из ее коллекции все предположения вплоть до неверного.
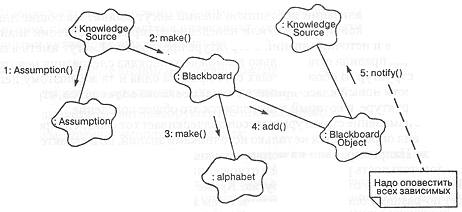
Можно действовать тоньше. Пусть мы предположили, что однобуквенное слово соответствует I (нужна гласная). Далее, сделано предположение, что некоторое двухбуквенное сочетание - это NN (нужны согласные). Если первое предположение окажется ошибочным, то второе вполне может быть сохранено. При таком подходе класс Assumption нужно дополнить еще одним методом, регистрирующим связь предположений между собой (взаимозависимость). Реализацию этого поведения можно отложить на более поздний срок, поскольку оно мало влияет на архитектуру.
Добавление источников знаний
Теперь, когда определены ключевые абстракции информационной доски и механизмы выдвижения и проверки предположений, необходимо реализовать механизм вывода (класс InferenceEngine), связывающий все источники знаний в единое целое. Ранее уже упоминалось, что механизм вывода должен реализовать одну основную операцию, а именно выполнение правила, evaluateRules. Мы не будем на этом подробно останавливаться, поскольку реализация не влияет на проектные решения.
Убедившись в правильной работе механизма вывода, можно последовательно вводить в систему источники знаний. Целесообразность именно такого процесса объясняется двумя причинами:
В процессе реализации источников знании могут выявиться общие для нескольких источников правила и/или поведение. Например, источник знаний о структуре слов и источник знаний о структуре предложений могут иметь в своем составе общие правила относительно возможного порядка следования некоторых языковых структур. В обоих случаях суть правила одна и та же, поэтому целесообразно ввести новый класс-примесь StructureKnowledgeSource, отражающий знания о структуре, в который и помещается это общее поведение.
Такое изменение структуры классов подчеркивает тот факт. что процесс обработки правил определяется не только источниками знаний, но и характером объектов доски. Например, один из источников знаний может реализовывать прямую последовательность рассуждений в отношении одних объектов и обратную последовательность - в отношении других. Кроме того, различные источники знаний могут по-разному оперировать с одним и тем же объектом.
11.4. Сопровождение
Расширение функциональных возможностей
В этом разделе мы попытаемся улучшить возможности проектируемой системы и оценить ее гибкость.
В интеллектуальных системах очень важно наряду с решением задачи получить информацию о самом процессе поиска решения. Для этого нужно придать системе способность самоанализа: регистрировать ход активизации источников знаний, причины и характер выдвигаемых предположений и т.д., чтобы иметь возможность запросить у системы, по какой причине сделано конкретное предположение и к каким результатам оно приводит.
Для реализации такого свойства необходимо сделать две вещи. Во-первых, нужно ввести механизм трассировки действий контроллера и источников знаний, а во-вторых - модифицировать некоторые методы, чтобы они записывали соответствующую информацию. Идея состоит том, что действия источников знаний и контроллера регистрируются в некотором общем центральном хранилище.
Посмотрим, какие классы нам понадобятся. Прежде всего, введем класс Action, регистрирующий действия источников знаний и контроллера:
class Action {
public:
Action(KnowledgeSource* who, BlackboardObject* what, char* why);};
Action(Controller* who, KnowledgeSource* what, char* why);
Экземпляр данного класса создается, например, при активизации контроллером какого-либо источника знаний. При этом в аргумент who (кто) заносится указатель на контроллер, в аргумент what (что) - активный источник знаний, а в аргумент why (почему) - какое-либо пояснение (например, приоритет предположения).
Первая часть нашего нового механизма создана, вторая тоже не очень сложна. Посмотрим, где в нашей системе происходят основные события. Мы увидим, что основными являются следующие пять операций:
Для полноты нам остается только создать объект, отвечающий на вопросы пользователя системы: кто? что? когда? почему?. Спроектировать такой объект несложно, поскольку вся нужная для его работы информация может быть получена от экземпляров класса Actions.
Изменение технических требований
Если принятые проектные решения были реализованы правильно, то новые технические требования к системе могут быть удовлетворены при минимальных изменениях проекта. Допустим, что предъявлены три новые требования к данной системе:
Второе требование существенно сложнее, но разрешимо в рамках механизма доски. Это потребует введения новых источников знаний относительно шифров перестановки. Ключевые механизмы и абстракции при этом также полностью сохранятся, но потребуется введение новых классов, которые будут действовать в рамках существующих механизмов выдвижения предположений и вывода.
Труднее всего выполнить последнее требование, так как обучение компьютеров относится к области искусственного интеллекта. Можно, например, предложить контроллеру в тупиковых ситуациях обращаться за помощью к пользователю системы с просьбой выдвинуть предположение. Такие предположения (вкупе с последовательностью действий, которая завела в тупик) могут регистрироваться системой и позволят в дальнейшем избегать подобных тупиков. Такой простейший механизм обучения может быть введен в нашу систему без существенного изменения структуры классов и в рамках действующих механизмов.
Дополнительная литература
При рассмотрении архитектурных шаблонов Шоу (Shaw) [A 1991] обсуждает метафору информационной доски и другие базовые идеи.
Енглемор и Морган (Englemore and Morgan) [С 1988] дали исчерпывающее обсуждение информационных досок, включая их эволюцию, теорию, проектирование и приложение. Существует описание двух объектно-ориентированных систем информационных досок: ВВ1 из Стэнфорда и BLOB, разработанной для Британского министерства обороны. Другие полезные сведения относительно информационных досок могут быть найдены у Хайеса-Рота (Hayes-Roth) [J 1985] и Нии (Nii) [J 1986].
Подробное обсуждение индуктивного и дедуктивного подходов в системах формального вывода можно найти в работах Барра и Фейгенбаума (Barr and Feigenbamn) [J 1981], Брахмана и Левескье (Brachman and Levesque) [G 1985], Хайес-Рота, Ватермана и Лена (Hayes-Roth, Waterman, and Lenat) [J 1983], а также Винстона и Хорна (Winston and Horn) [G 1989].
Мейер и Матиас (Meyer and Matyas) [I 1982] рассмотрели сильные и слабые стороны разных шифров и алгоритмы их дешифровки.